Hourly Usage
Performance Metrics
Avg. Total Time
10.12s
Avg. TTFT
12.94s
Avg. Prefill TPS
79.52
Avg. Gen TPS
13.27
Model Information
Context Size
32768
Quantization
r64
Engine
aphrodite
Creation Method
LoRA Finetune
Model Type
Llama70B
Chat Template
Llama 3
Reasoning
No
Vision
No
Parameters
70B
Added At
1/13/2025
license: llama3.3 language:
- en base_model:
- meta-llama/Llama-3.3-70B-Instruct
widget:
- text: "Negative_LLAMA_70B" output: url: https://huggingface.co/SicariusSicariiStuff/Negative_LLAMA_70B/resolve/main/Images/Negative_LLAMA_70B.png

It's January 2025, and still, there are very few models out there that have successfully tackled LLM's positivity bias. LLAMA 3.3 was received in the community with mixed feelings. It is an exceptional assistant, and superb at instruction following (highest IFEVAL to date, and by a large margin too.)
The problem- it is very predictable, dry, and of course, plaugued with positivity bias like all other LLMs. Negative_LLAMA_70B is not an unalignment-focused model (even though it's pretty uncensored), but it is my attempt to address positivity bias while keeping the exceptional intelligence of the LLAMA 3.3 70B base model. Is the base 3.3 smarter than my finetune? I'm pretty sure it is, however, Negative_LLAMA_70B is still pretty damn smart.
The model was NOT overcooked with unalignment, so it won't straight up throw morbid or depressing stuff at you, but if you were to ask it to write a story, or engage in an RP, you would notice slightly darker undertones. In a long trip, the character takes in a story- their legs will be hurt and would feel tired, in Roleplay when you seriously piss off a character- it might hit you (without the need to explicitly prompt such behavior in the character card).
Also, toxic-dpo and other morbid unalignment datasets were not used. I did include a private dataset that should allow total freedom in both Roleplay & Creative writing, and quite a lot of various assistant-oriented tasks.
If you ask the assistant to analyze De Sades' work in graphic detail, you will not have refusals from Negative_LLAMA_70B.
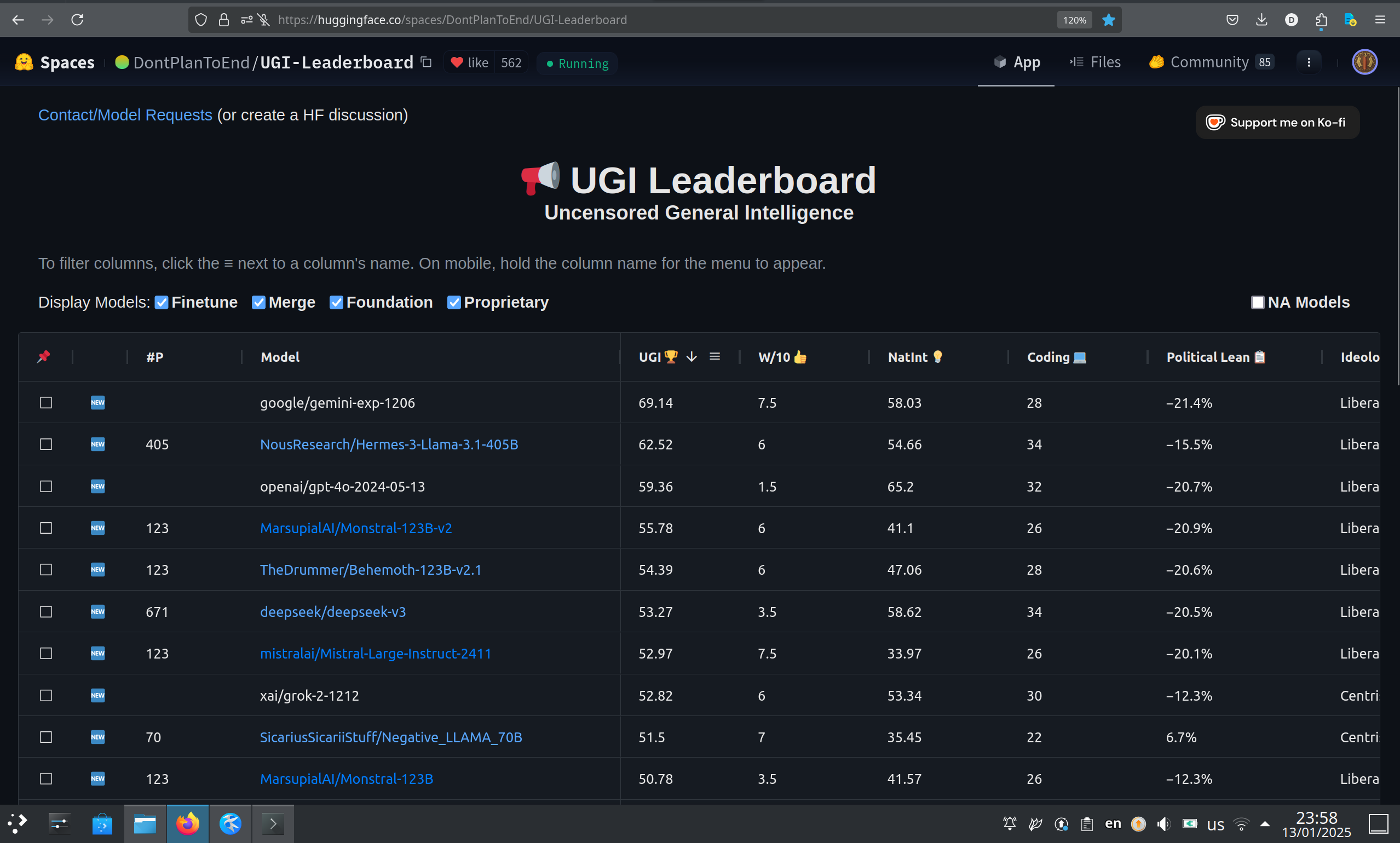
Update on UGI scores: Achieved the highest score in the world as of 13/01/2025 for 70B models
- See UGI section for more details
- Neutral centrist political view
- Total UGI score: 51.5
TL;DR
- Highest rated 70B model in the world in the UGI leaderboard
- Strong Roleplay & Creative writing abilities.
- Less positivity bias.
- Very smart assistant with low refusals.
- Exceptionally good at following the character card.
- Characters feel more 'alive', and will occasionally initiate stuff on their own (without being prompted to, but fitting to their character).
- Strong ability to comprehend and roleplay uncommon physical and mental characteristics.
Important: Make sure to use the correct settings!
Available quantizations:
- Original: FP16
- GGUF & iMatrix: bartowski
- EXL2: 3.5 bpw | 4.0 bpw | 5.0 bpw | 6.0 bpw | 7.0 bpw | 8.0 bpw
- EXL3: 1.6 bpw | 2.15 bpw | 2.5 bpw
- GPTQ: 4-Bit-32 | 4-Bit-128
- Specialized: FP8
Model Details
-
Intended use: Role-Play, Creative Writing, General Tasks.
-
Censorship level: Low
-
7 / 10 (10 completely uncensored)
UGI score:
This model was trained with various private datasets, meticulously filtered book data, and creative writing data. All checked and verified by hand, this took a tremendous amount of time, but I feel the end result was worth it.
Regarding Roleplay: Roleplay data was filtered for quality, and several private datasets of exceptional quality (fully organic) were used for the first time. What is exceptional quality? Very good writing, filtered and fixed by hand, deslopped and augmented further still. This portion of the roleplay dataset is small, for now. Synthetic roleplay data was deslopped, but it's not perfect. I do, however, feel like the small portion of the high-quality data greatly improved the roleplay experience and gave the model some unique takes. It feels much more human, at times.
More than 50% of the data used for training is entirely organic (taken from books), and the synthetic part was mostly deslopped. I've used some Wikipedia data of controversial topics for some soft decensoring too (which just goes to show you how ridiculously censored most corpo models are, when they will straight up refuse to give you info that is widely available on Wikipedia). This achieves both goals of less GPTisms and decensoring the model while retaining intelligence. The said data was further augmented using AI and deslopped by hand on the spot.
So, Is there still slop? Of course, there is. There are whispers, dances, and the like- but they do not come from the training data, so hopefully, you will encounter them a little bit more rarely now.
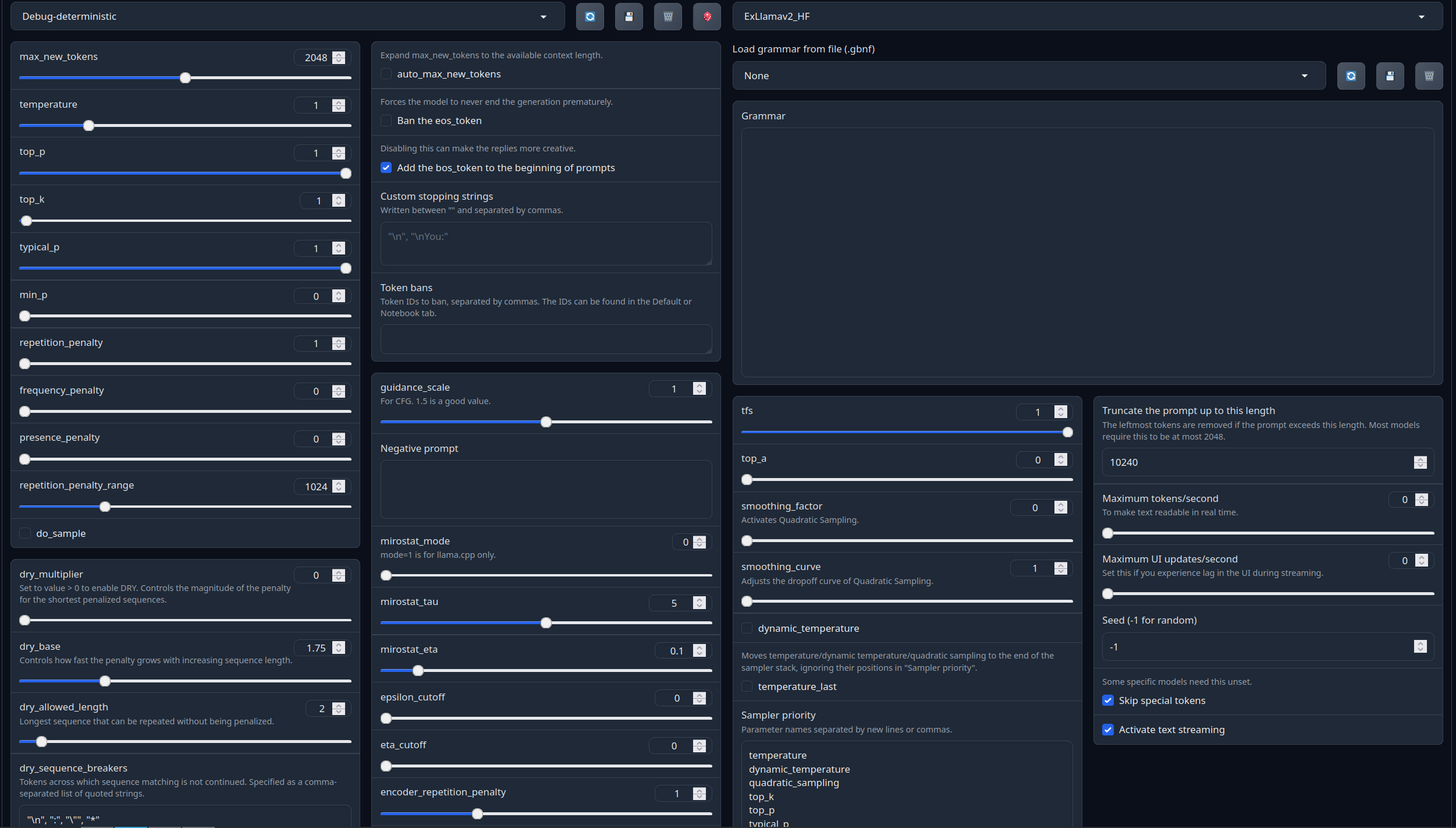
Recommended settings for assistant mode
Full generation settings: Debug Deterministic.
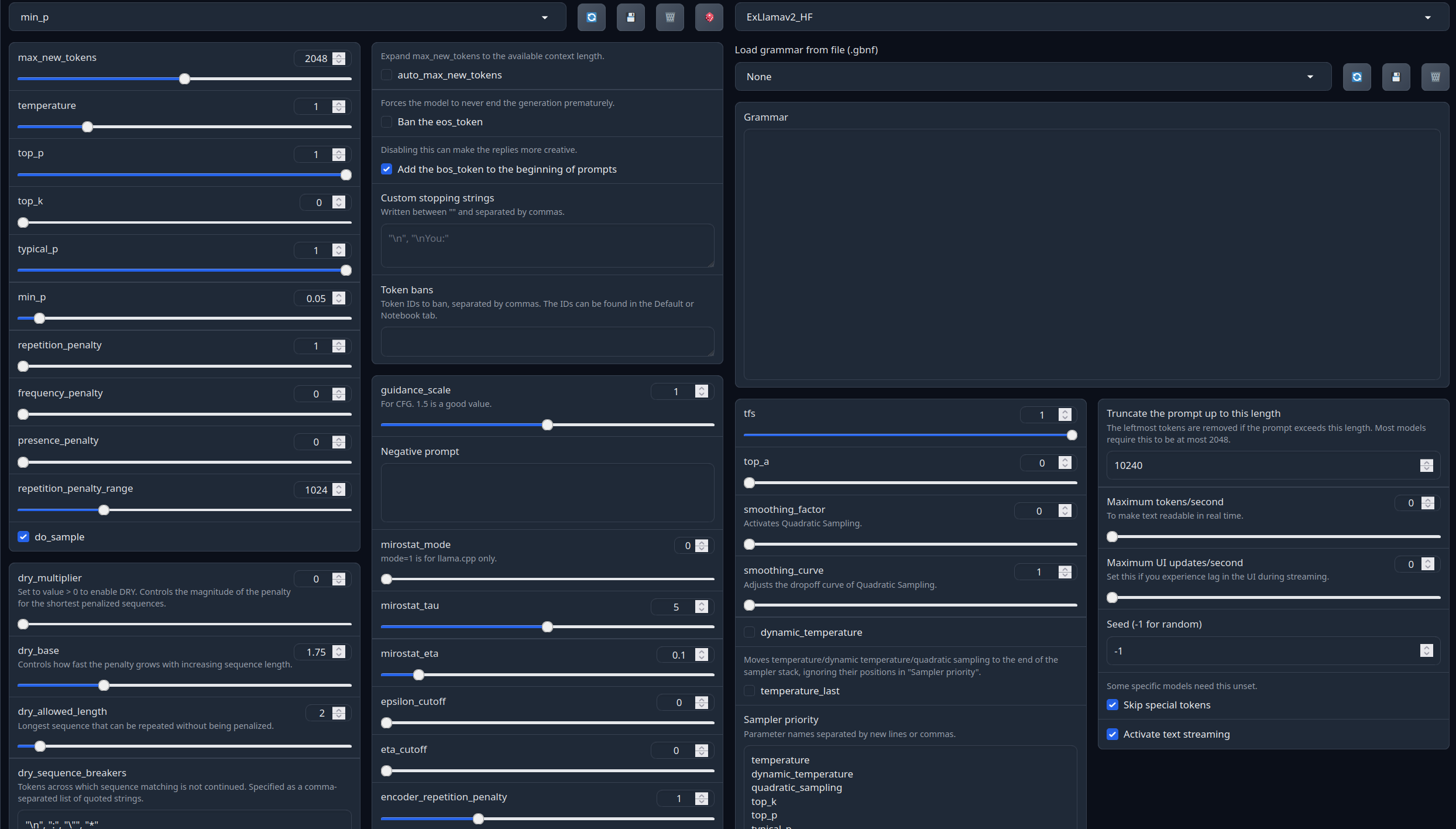
Full generation settings: min_p.
Recommended settings for Roleplay mode
Roleplay settings:.
A good repetition_penalty range is between 1.12 - 1.15, feel free to experiment.With these settings, each output message should be neatly displayed in 1 - 5 paragraphs, 2 - 3 is the most common. A single paragraph will be output as a response to a simple message ("What was your name again?").
min_P for RP works too but is more likely to put everything under one large paragraph, instead of a neatly formatted short one. Feel free to switch in between.
(Open the image in a new window to better see the full details)
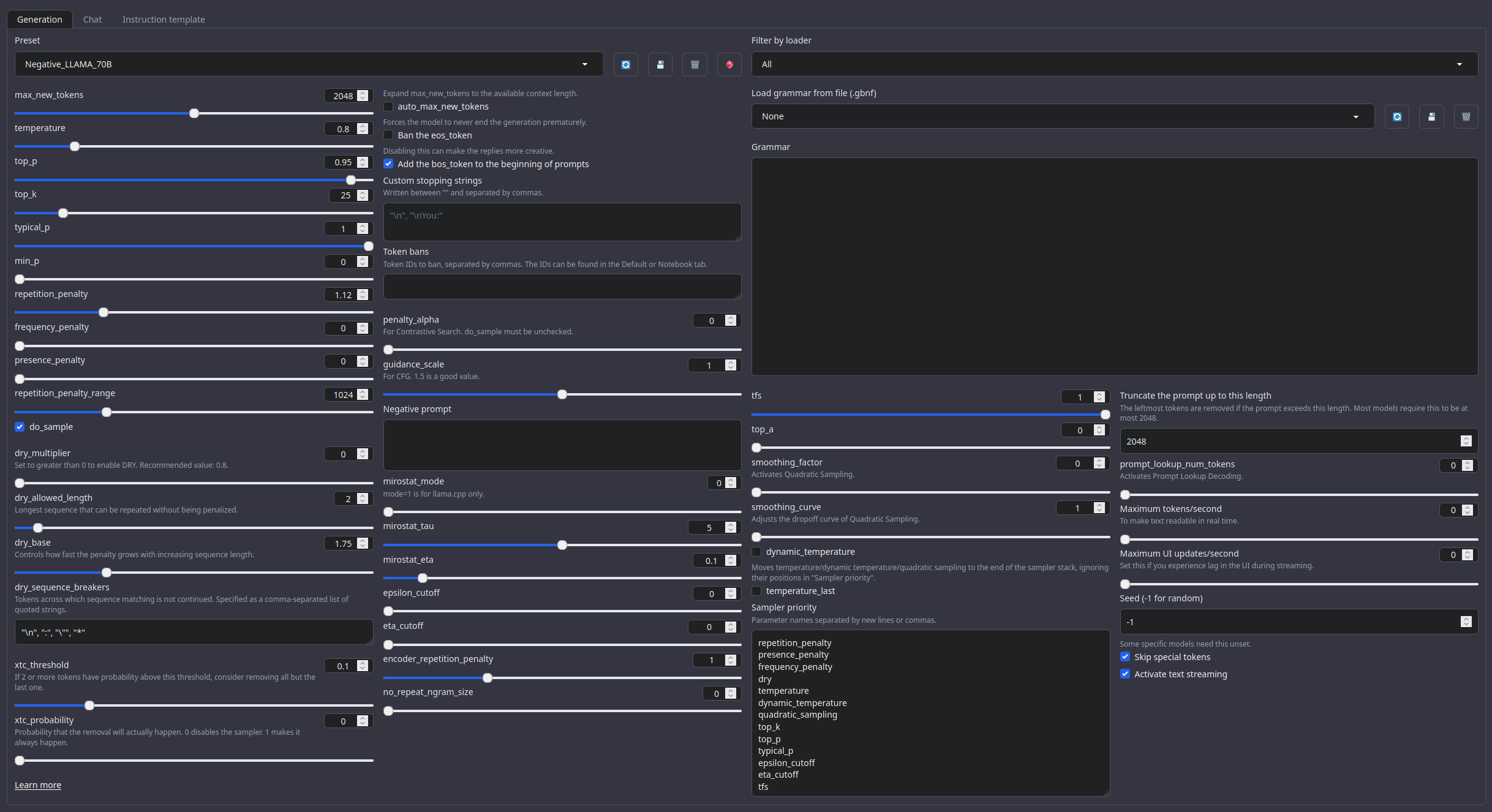
temperature: 0.8
top_p: 0.95
top_k: 25
typical_p: 1
min_p: 0
repetition_penalty: 1.12
repetition_penalty_range: 1024
Roleplay format: Classic Internet RP
*action* speech *narration*
- min_p will bias towards a single big paragraph.
- The recommended RP settings will bias towards 1-3 small paragraphs (on some occasions 4-5)
Regarding the format:
It is HIGHLY RECOMMENDED to use the Roleplay \ Adventure format the model was trained on, see the examples below for syntax. It allows for a very fast and easy writing of character cards with minimal amount of tokens. It's a modification of an old-skool CAI style format I call SICAtxt (Simple, Inexpensive Character Attributes plain-text):
SICAtxt for roleplay:
X's Persona: X is a .....
Traits:
Likes:
Dislikes:
Quirks:
Goals:
Dialogue example
SICAtxt for Adventure:
Adventure: <short description>
$World_Setting:
$Scenario:
Model instruction template: Llama-3-Instruct
<|begin_of_text|><|start_header_id|>system<|end_header_id|>
{system_prompt}<|eot_id|><|start_header_id|>user<|end_header_id|>
{input}<|eot_id|><|start_header_id|>assistant<|end_header_id|>
{output}<|eot_id|>
Other recommended generation Presets:
Midnight Enigma
``` max_new_tokens: 512 temperature: 0.98 top_p: 0.37 top_k: 100 typical_p: 1 min_p: 0 repetition_penalty: 1.18 do_sample: True ```Divine Intellect
``` max_new_tokens: 512 temperature: 1.31 top_p: 0.14 top_k: 49 typical_p: 1 min_p: 0 repetition_penalty: 1.17 do_sample: True ```simple-1
``` max_new_tokens: 512 temperature: 0.7 top_p: 0.9 top_k: 20 typical_p: 1 min_p: 0 repetition_penalty: 1.15 do_sample: True ```Your support = more models
My Ko-fi page (Click here)Citation Information
@llm{Negative_LLAMA_70B,
author = {SicariusSicariiStuff},
title = {Negative_LLAMA_70B},
year = {2025},
publisher = {Hugging Face},
url = {https://huggingface.co/SicariusSicariiStuff/Negative_LLAMA_70B}
}
Benchmarks
Update: OK, I tried submitting this like x15 times already, seriously. I tried opening an issue on the HF leaderboard. No benchmarks, sorry I tried. Godbless UGI leaderboard, see it for more details (coding and other stuff is also measured).
Other stuff
- SLOP_Detector Nuke GPTisms, with SLOP detector.
- LLAMA-3_8B_Unaligned The grand project that started it all.
- Blog and updates (Archived) Some updates, some rambles, sort of a mix between a diary and a blog.