Text Generation API Documentation
Generate text using the Arli AI Text Generation endpoints.
Image Generation API DocsMy API KeysOverview
The Arli AI Text Generation API provides endpoints for generating text via completions or chat completions, tokenizing text, and retrieving information about available models.
Powered by Aphrodite-Engine and vLLM
Arli AI Text Generation is powered by both Aphrodite-Engine and vLLM depending on the models. As such most of our available generation parameters will be similar to those available in Aphrodite-Engine.
https://github.com/aphrodite-engine/aphrodite-enginehttps://github.com/vllm-project/vllmAuthentication & Usage
All Text Generation API endpoints require authentication using a Bearer Authentication via the Authorization header. Replace {ARLIAI_API_KEY} in the examples with your actual API key.
Ensure you have access granted to the specific Text Generation models you intend to use. Free accounts are able to use each model for a maximum of 5 requests every 2 days for testing purposes. Text generation requests are subject to rate limits and concurrency limits based on your account plan. Exceeding limits may result in temporary account restrictions.
API Key parameter overrides (set in your account settings) will merge with and take precedence over parameters sent in the request body for allowed parameters.
Parallel Requests
The number of requests you can make at the same time for a model is determined by the parallel requests allowed for your account.
If you try to send more requests in parallel than allowed, the request will be blocked.
Models endpoint
Check for models available to you using the models endpoint.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
import requests
import json
url = "https://api.arliai.com/v1/models"
payload = ""
headers = {
'Content-Type': 'application/json',
'Authorization': 'Bearer {ARLIAI_API_KEY}'
}
response = requests.request("GET", url, headers=headers, data=payload)
print(response.text)Tokenize endpoint
Tokenize text and get token count using the tokenize endpoint.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
import requests
import json
url = "https://api.arliai.com/v1/tokenize"
payload = json.dumps({
"model": "Mistral-Nemo-12B-Instruct-2407",
"messages": [
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Hello!"},
{"role": "assistant", "content": "Hi!, how can I help you today?"},
{"role": "user", "content": "Say hello!"}
]
})
headers = {
'Content-Type': 'application/json',
'Authorization': f"Bearer {ARLIAI_API_KEY}"
}
response = requests.request("POST", url, headers=headers, data=payload)Inference Parameter Override
You can override parameters sent to the API on a per-API-key basis. This is useful for use in LLM front-ends that do not expose parameters that you want to use or don't support our custom parameters such as "multi_models" or "multiplier".
You can either use the sliders or directly type in the parameters in the textbox using JSON format. Enabled overrides will have a blue dot beside the name and in the JSON.
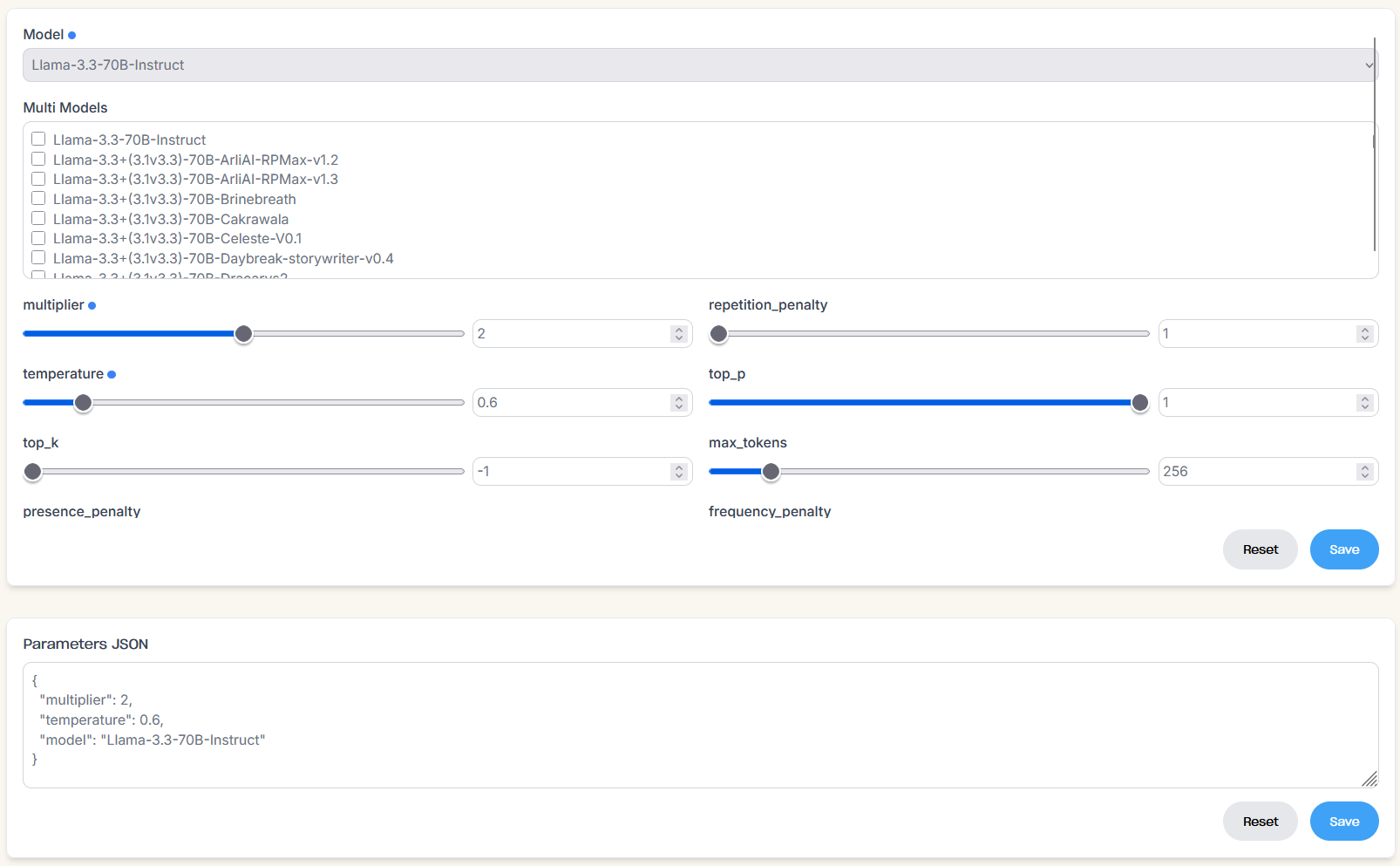
Custom Arli AI parameters
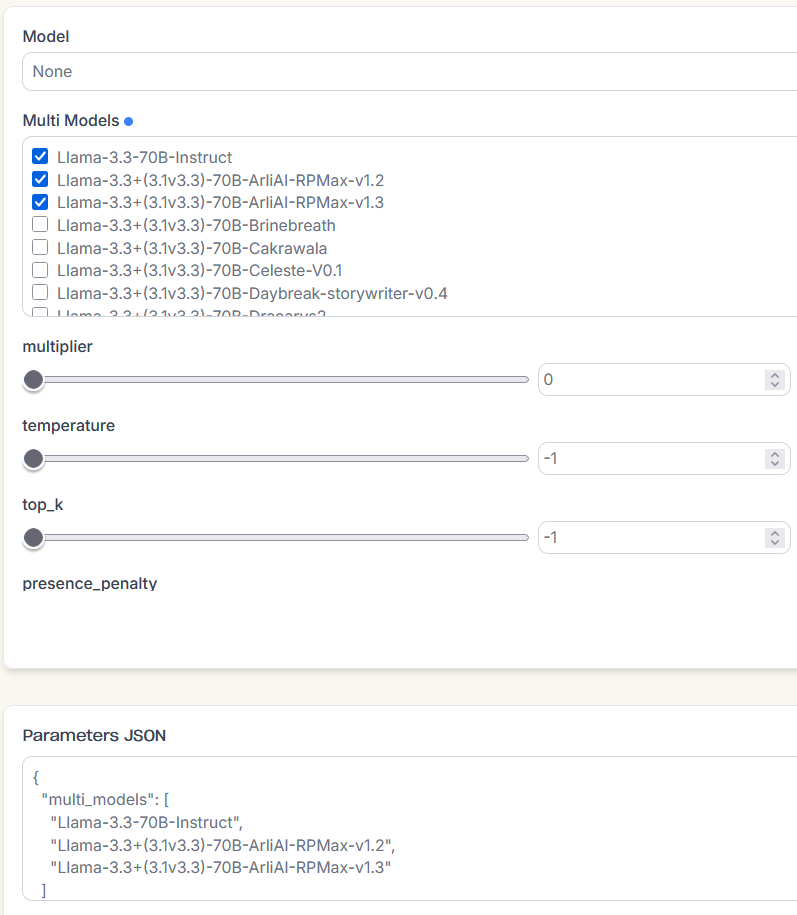
Multi Models
Request a list of models you want to use for generation, a model will be chosen at random during request time.
Multiplier
Multiplier for a finetuned model's LoRA alpha value. Higher value means stronger effect from the finetune. 2x and 4x supported.

Chat completions and Text completions endpoint parameter options
Use the examples in the Quick-Start page for working copy-pastable examples. Copy paste parameters that you need from here.
These example API request are to show how to use the parameters, some options might conflict and the values are arbitrary.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
import requests
import json
url = "https://api.arliai.com/v1/chat/completions" # Can also use /v1/completions endpoint
payload = json.dumps({
"model": "Mistral-Nemo-12B-Instruct-2407",
"multi_models": ["Mistral-Nemo-12B-Instruct-2407", "Mistral-Small-24B-Instruct-2501"],
"multiplier": 2,
# Use messages for /chat/completions
"messages": [
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Hello!"},
{"role": "assistant", "content": "Hi! How can I help you today?"},
{"role": "user", "content": "Say hello!"}
],
# Use prompt for /completions
"prompt": "<|begin_of_text|><|start_header_id|>system<|end_header_id|>
You are an assistant AI.<|eot_id|><|start_header_id|>user<|end_header_id|>
Hello there!<|eot_id|><|start_header_id|>assistant<|end_header_id|>
",
# Most important parameters
"repetition_penalty": 1.1,
"temperature": 0.7,
"top_p": 0.9,
"top_k": 40,
"max_tokens": 1024,
"stream": True,
"n": 1,
"min_tokens": 20,
# Extra parameters
"seed": 0,
"presence_penalty": 0.6,
"frequency_penalty": 0.6,
"dynatemp_min": 0.5,
"dynatemp_max": 1.0,
"dynatemp_exponent": 1,
"smoothing_factor": 0.0,
"smoothing_curve": 1.0,
"top_a": 0,
"min_p": 0,
"tfs": 1,
"eta_cutoff": 1e-4,
"epsilon_cutoff": 1e-4,
"typical_p": 1,
"length_penalty": 1.0,
"early_stopping": False,
"stop": [],
"stop_token_ids": [],
"include_stop_str_in_output": False,
"ignore_eos": False,
"logprobs": 5,
"prompt_logprobs": 0,
"detokenize": True,
"skip_special_tokens": True,
"spaces_between_special_tokens": True,
"logits_processors": [],
"xtc_threshold": 0.1,
"xtc_probability": 0,
"guided_json": {"type": "object", "properties": {"response": {"type": "string"}}},
"guided_regex": "^\w+$",
"guided_choice": ["Yes", "No", "Maybe"],
"guided_decoding_backend": "regex",
"guided_whitespace_pattern": "\s+",
"truncate_prompt_tokens": None,
"no_repeat_ngram_size": 2,
"nsigma": 1.5,
"dry_multiplier": 1.0,
"dry_base": 1.75,
"dry_allowed_length": 2,
"dry_sequence_breaker_ids": [],
"dry_range": 50,
"skew": 0.0,
"sampler_priority": []
})
headers = {
'Content-Type': 'application/json',
'Authorization': f"Bearer {ARLIAI_API_KEY}"
}
response = requests.post(url, headers=headers, data=payload)API Parameters Explanation
| Parameter | Engine | Explanation |
|---|---|---|
| model | aphrodite,vllm | The chosen model to use for generation. |
| multi_models | aphrodite,vllm | List of models to use for generation. Chosen randomly during the request. |
| multiplier | aphrodite,vllm | Multiplier for a finetuned model's LoRA alpha value. Higher value means stronger effect from the finetune. 0.5x, 2x and 4x supported. |
| n | aphrodite,vllm | Number of output sequences to return for the given prompt. |
| min_tokens | aphrodite,vllm | Minimum number of tokens to generate per output sequence before EOS or stop tokens are generated. |
| presence_penalty | aphrodite,vllm | Float that penalizes new tokens based on whether they appear in the generated text so far. Values > 0 encourage the model to use new tokens, while values < 0 encourage the model to repeat tokens. |
| frequency_penalty | aphrodite,vllm | Float that penalizes new tokens based on their frequency in the generated text so far. Values > 0 encourage the model to use new tokens, while values < 0 encourage the model to repeat tokens. |
| repetition_penalty | aphrodite,vllm | Float that penalizes new tokens based on their frequency in the generated text so far. Freq_pen is applied additively while rep_pen is applied multiplicatively. Must be in [1, inf). Set to 1 to disable the effect. |
| no_repeat_ngram_size | aphrodite,vllm | Size of the n-grams to prevent repeating. 1 would mean no token can appear twice. 2 would mean no pair of consecutive tokens can appear twice. |
| temperature | aphrodite,vllm | Float that controls the randomness of the sampling. Lower values make the model more deterministic, while higher values make the model more random. Zero means greedy sampling. |
| top_p | aphrodite,vllm | Float that controls the cumulative probability of the top tokens to consider. Must be in (0, 1]. Set to 1 to consider all tokens. |
| top_k | aphrodite,vllm | Integer that controls the number of top tokens to consider. Set to -1 to consider all tokens. |
| top_a | aphrodite,vllm | Float that controls the cutoff for Top-A sampling. Exact cutoff is top_a*max_prob**2. Must be in [0, inf], 0 to disable. |
| min_p | aphrodite,vllm | Float that controls the cutoff for min-p sampling. Exact cutoff is min_p*max_prob. Must be in [0, 1], 0 to disable. |
| tfs | aphrodite,vllm | Float that controls the cumulative approximate curvature of the distribution to retain for Tail Free Sampling. Must be in (0, 1]. Set to 1 to disable. |
| eta_cutoff | aphrodite,vllm | Float that controls the cutoff threshold for Eta sampling (a form of entropy adaptive truncation sampling). Threshold is computed as min(eta, sqrt(eta)*entropy(probs)). Specified in units of 1e-4. Set to 0 to disable. |
| epsilon_cutoff | aphrodite,vllm | Float that controls the cutoff threshold for Epsilon sampling (simple probability threshold truncation). Specified in units of 1e-4. Set to 0 to disable. |
| typical_p | aphrodite,vllm | Float that controls the cumulative probability of tokens closest in surprise to the expected surprise. Must be in (0, 1]. Set to 1 to disable. |
| dynatemp_min | aphrodite,vllm | Minimum temperature for dynamic temperature sampling. Range [0, inf). |
| dynatemp_max | aphrodite,vllm | Maximum temperature for dynamic temperature sampling. Range [0, inf). |
| dynatemp_exponent | aphrodite,vllm | Exponent for dynamic temperature sampling. Range [0, inf). |
| smoothing_factor | aphrodite,vllm | Smoothing factor for Quadratic Sampling. |
| smoothing_curve | aphrodite,vllm | Smoothing curve for Cubic Sampling. |
| seed | aphrodite,vllm | Random seed to use for the generation. |
| length_penalty | aphrodite,vllm | Penalizes sequences based on their length. Used in beam search. |
| stop | aphrodite,vllm | List of strings that stop the generation when they are generated. The returned output will not contain the stop strings. |
| stop_token_ids | aphrodite,vllm | List of token IDs that stop the generation when they are generated. The returned output will contain the stop tokens unless they are special tokens. |
| include_stop_str_in_output | aphrodite,vllm | Whether to include the stop strings in the output text. Defaults to False. |
| ignore_eos | aphrodite,vllm | Whether to ignore the EOS token and continue generating tokens after the EOS token is generated. |
| max_tokens | aphrodite,vllm | Maximum number of tokens to generate per output sequence. |
| min_tokens | aphrodite,vllm | Minimum number of tokens to generate per output sequence before EOS or stop tokens are generated. |
| logprobs | aphrodite,vllm | Number of log probabilities to return per output token. When set to None, no probability is returned. |
| prompt_logprobs | aphrodite,vllm | Number of log probabilities to return per prompt token. |
| detokenize | aphrodite,vllm | Whether to detokenize the output. Defaults to True. |
| skip_special_tokens | aphrodite,vllm | Whether to skip special tokens in the output. Defaults to True. |
| spaces_between_special_tokens | aphrodite,vllm | Whether to add spaces between special tokens in the output. Defaults to True. |
| logits_processors | aphrodite,vllm | List of functions that modify logits based on previously generated tokens and optionally prompt tokens. |
| logit_bias | aphrodite,vllm | List of LogitsProcessors to change the probability of token prediction at runtime. |
| truncate_prompt_tokens | aphrodite,vllm | If set to an integer k, will use only the last k tokens from the prompt (left-truncation). Default: None (no truncation). |
| xtc_threshold | aphrodite | In XTC sampling, if 2 or more tokens have a probability above this threshold, consider removing all but the last one. Disabled: 0. |
| xtc_probability | aphrodite | The probability that the removal will happen in XTC sampling. Set to 0 to disable. Default: 0. |
| guided_json | aphrodite,vllm | If specified, the output will follow the JSON schema. Can be a JSON string or a Python dictionary. |
| guided_regex | aphrodite,vllm | If specified, the output will follow the regex pattern. |
| guided_choice | aphrodite,vllm | If specified, the output will be exactly one of the provided choices (a list of strings). |
| guided_decoding_backend | aphrodite,vllm | Overrides the default guided decoding backend for this specific request. Must be either "outlines" or "lm-format-enforcer". |
| guided_whitespace_pattern | aphrodite,vllm | Overrides the default whitespace pattern for guided JSON decoding. |
| nsigma | aphrodite, | Number of standard deviations from the maximum logit to use as a cutoff threshold. Tokens with logits below (max_logit - nsigma * std_dev) are filtered out. Higher values (e.g. 3.0) keep more tokens, lower values (e.g. 1.0) are more selective. Must be positive. 0 to disable. |
| dry_multiplier | aphrodite | Float that controls the magnitude of the DRY sampling penalty. Higher values create stronger penalties against repetition. The penalty is multiplied by this value before being applied. Must be non-negative. 0 disables the sampler. |
| dry_base | aphrodite | Base for the exponential growth of the DRY sampling penalty. Controls how quickly the penalty increases with longer repeated sequences. Must be greater than 1. Higher values (e.g. 2.0) create more aggressive penalties for longer repetitions. Defaults to 1.75. |
| dry_allowed_length | aphrodite | Maximum number of tokens that can be repeated without incurring a DRY sampling penalty. Sequences longer than this will be penalized exponentially. Must be at least 1. Defaults to 2. |
| dry_sequence_breaker_ids | aphrodite | List of token IDs that stop the matching of repeated content. These tokens will break up the input into sections where repetition is evaluated separately. Common examples are newlines, quotes, and other structural tokens. Defaults to None. |
| dry_range | aphrodite | The range of tokens (input + output) to apply the DRY sampler. |
| skew | aphrodite | Bias the token selection towards higher or lower probability tokens. Defaults to 0 (disabled). |
| sampler_priority | aphrodite | A list of integers to control the order in which samplers are applied. |